
Unprecedented Bidding War Erupts Over Anysphere, Creator of Popular AI Coding Assistant Cursor
Technology News
Zaker Adham
09 November 2024
02 October 2024
|
Zaker Adham
Summary
Summary
Recent research on transformer-based large language models (LLMs) like GPT-2 has highlighted a curious phenomenon—unused and under-trained tokens that can unexpectedly influence model performance. These tokens either weren’t represented adequately in the training data or were rarely encountered, which can lead to issues such as model hallucinations and inaccurate outputs. In this article, we explore the distinction between unused and under-trained tokens, showcase experiments using GPT-2 Small, and discuss techniques for identifying such tokens.
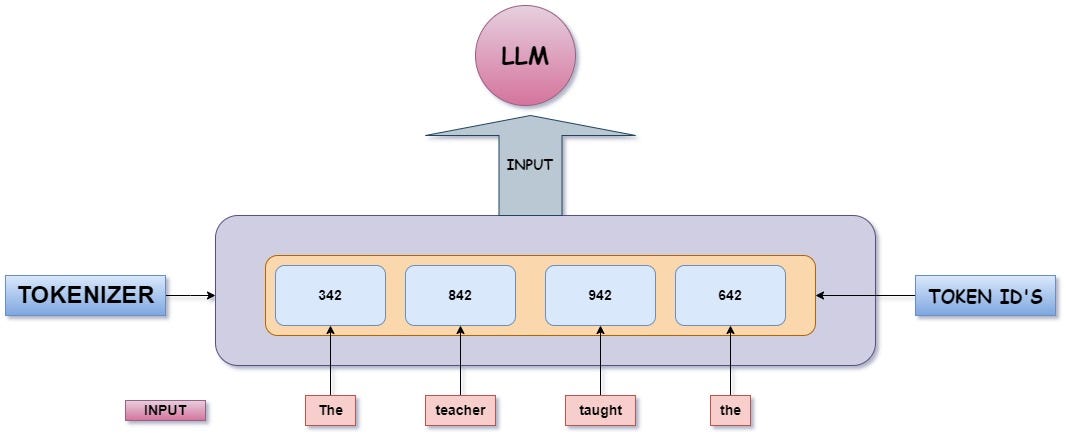
Unused tokens are part of the model's vocabulary but were scarcely encountered during the training phase. Under-trained tokens, on the other hand, may or may not exist in the vocabulary but were insufficiently represented during training. Ideally, both types should have low probabilities of being generated. However, in practice, unused tokens may still appear in model outputs, occasionally leading to undesirable results.
Example: Generating Unused Tokens We conducted an experiment with GPT-2 Small to illustrate how it handles unused tokens. One of the tokens we tested was "ú" (U+00FA). The task was simple—get the model to repeat the token "ú" upon input. Unfortunately, GPT-2 Small struggled with this task, outputting garbled text like "Output: - ß, - -, " instead of the expected result. In contrast, common tokens such as "a" were predicted correctly, showing how unused tokens can affect model performance.
To further understand how unused tokens affect outputs, we generated repeated random tokens from GPT-2 Small. For unused token indices ranging from 177 to 188, the model exhibited poor performance. We observed that log probabilities for repeated sequences were significantly lower compared to commonly used tokens, indicating the challenge LLMs face in dealing with under-trained tokens.
One of the main reasons for this issue is the separation between tokenization and model training. Tokens that aren’t sufficiently trained can sometimes appear in model outputs, leading to unexpected behaviors. Recent techniques have emerged to automatically identify under-trained tokens, such as analyzing output embeddings and computing cosine distances between tokens. This helps in flagging under-trained tokens that may cause the model to behave unpredictably.
Example: Detecting Unused Tokens In another experiment, we sliced the logits tensor in GPT-2 Small to focus on the unused token range (177 to 188). Interestingly, we found that some unused tokens had a logit value of approximately -1.7, indicating a non-negligible probability of appearing in model outputs. This underscores the potential for unused tokens to influence model behavior, despite their low occurrence during training.
Unused and under-trained tokens can pose significant challenges in LLMs, leading to unintended outputs and hallucinations. Techniques like analyzing embeddings help identify these tokens, allowing researchers to improve model reliability. By addressing these issues, we can ensure LLMs generate more accurate and appropriate responses.
Technology News
Zaker Adham
09 November 2024

Technology News
Zaker Adham
09 November 2024

Technology News
Zaker Adham
09 November 2024

Technology News
Zaker Adham
07 November 2024